
![]()
Colossal-AI: 大規模AI モデルをより安く、高速に、そしてアクセスしやすくする

![]()

セットアップをスキップしてください。HPC-AI Cloud 上で強力な事前構成済み Colossal-AI 環境にアクセスしてください。
ワンクリックでモデルを訓練し、AI ワークロードをスケーリングしてください!
- NVIDIA Blackwell B200s: 次世代 AI パフォーマンスを体験してください(ベンチマークを参照)。現在クラウドから $2.47/時間 で利用可能です。
- 費用対効果に優れた H200 クラスター: わずか $1.99/時間 のオンデマンドレンタルで最高のパフォーマンスを取得してください。

手間を省きましょう。HPC-AI Model APIs を通じて、強力で長いコンテキストに対応した LLM にシームレスにアクセスできます。
HPC-AI Model APIs で AI エージェント、チャットボット、RAG アプリケーションを構築しましょう!
-
最新で最高のモデル:Kimi 2.5、MiniMax 2.5、GLM 5.1 で最先端のパフォーマンスを体験してください。200 万以上のコンテキストウィンドウと複雑なコーディングタスクに最適です。
-
比類のない価格:API エンドポイントの過剰な支払いを止めましょう。OpenRouter より最大 50% 安い最高品質の推論速度を取得できます。

これらのパフォーマンス向上が実世界のアプリケーションにどのように変わるかを確認するために、Llama のようなモデルに対して Colossal-AI を使用した大規模言語モデルのトレーニングベンチマークを実施しました。テストは 7B および 70B モデルに対して 8 枚および 16 枚の GPU 構成で実行されました。
| GPU | GPU 枚数 | モデルサイズ | 並列処理方式 | DP あたりのバッチサイズ | シーケンス長 | スループット | TFLOPS/GPU | ピークメモリ(MiB) |
|---|---|---|---|---|---|---|---|---|
| H200 | 8 | 7B | zero2(dp8) | 36 | 4096 | 17.13 samp/s | 534.18 | 119040.02 |
| H200 | 16 | 70B | zero2 | 48 | 4096 | 3.27 samp/s | 469.1 | 150032.23 |
| B200 | 8 | 7B | zero1(dp2)+tp2+pp4 | 128 | 4096 | 25.83 samp/s | 805.69 | 100119.77 |
| H200 | 16 | 70B | zero1(dp2)+tp2+pp4 | 128 | 4096 | 5.66 samp/s | 811.79 | 100072.02 |
Colossal-AI ベンチマークの結果は、最も実用的な知見を提供します。8 枚の GPU 上の 7B モデルの場合、B200 は 50% 高いスループットを達成し、GPU あたりの TFLOPS が大幅に増加しました。16 枚の GPU 上の 70B モデルの場合、B200 は再び明らかな利点を示し、スループットと GPU あたりの TFLOPS が 70% 以上高くなりました。これらの数値は、B200 のパフォーマンス向上が大規模モデルのトレーニング時間の短縮に直結することを示しています。
- [2025/02] DeepSeek 671B ファインチューニングガイドが公開されました—ワンクリックでアップグレードされた DeepSeek スイートをアンロック、AI プレーヤーが大喜び!
- [2024/12] ビデオ生成モデルの開発コストが 50% 削減されました!H200 GPU バウチャー付きのオープンソースソリューションが利用可能になりました [code] [バウチャー]
- [2024/10] 低コストな Sora のようなアプリを構築する方法は?あなたのためのソリューション
- [2024/09] シンガポール・スタートアップ HPC-AI Tech が動画生成 AI モデルと GPU プラットフォーム構築のためにシリーズ A で 5,000 万ドルの資金調達を確保
- [2024/09] AI 大規模モデルのトレーニングコストを 30% 削減するには、FP8 混合精度トレーニングアップグレードからたった 1 行のコードが必要
- [2024/06] Open-Sora はオープンソースを継続:ワンクリックで 16 秒間の 720p HD ビデオを生成、モデルウェイトは使用可能
- [2024/05] 大規模 AI モデルの推論速度が 2 倍に、Colossal-Inference オープンソースリリース
- [2024/04] Open-Sora が大規模なアップグレードを発表:シングルショット 16 秒間のビデオ生成と 720p 解像度を備えたオープンソースを採用
- [2024/04] 推論、ファインチューニング、事前トレーニングの最もコスト効率的なソリューション、LLaMA3 シリーズ向けにカスタマイズ
- Colossal-AIを選ぶ理由
- 特徴
- 実世界でのColossal-AIの応用
- 並列トレーニングのデモ
- 単一GPU向けトレーニングのデモ
- 推論
- インストール
- Dockerの使用
- コミュニティ
- 貢献
- 引用

Prof. James Demmel (UC Berkeley): Colossal-AIはAIモデルのトレーニングを効率的で、簡単で、スケーラブルにします。
(トップに戻る)
Colossal-AIは、あなたのための並列コンポーネントのコレクションを提供します。私たちの目標は、ノートパソコンでモデルを書くのと同じように、分散深層学習モデルを書くことをサポートすることです。わずか数行で分散トレーニングと推論を開始するためのユーザーフレンドリーなツールを提供します。
-
並列化戦略
-
異種メモリ管理
-
使いやすさ
- 設定ファイルに基づく並列化
(トップに戻る)
Open-Sora:Sora風動画生成モデルの完全なモデルパラメータ、トレーニング詳細、およびすべてを開示 [コード] [ブログ] [モデルの重み] [デモ] [GPU クラウド プレイグラウンド] [OpenSora 画像]

(トップに戻る)
[GPU クラウド プレイグラウンド] [LLaMA3 イメージ]
-
7B: わずか数百ドルで半日のトレーニングにより、主流の大規模モデルと同様の結果が得られます。オープンソースで商用制約のないドメイン特化型 LLM ソリューションです。 [code] [blog] [HuggingFace モデルウェイト] [Modelscope モデルウェイト]
-
13B: わずか 5000 米ドルで精緻な 13B プライベートモデルを構築できます。 [code] [blog] [HuggingFace モデルウェイト] [Modelscope モデルウェイト]
| モデル | バックボーン | 消費トークン数 | MMLU (5-shot) | CMMLU (5-shot) | AGIEval (5-shot) | GAOKAO (0-shot) | CEval (5-shot) |
|---|---|---|---|---|---|---|---|
| Baichuan-7B | - | 1.2T | 42.32 (42.30) | 44.53 (44.02) | 38.72 | 36.74 | 42.80 |
| Baichuan-13B-Base | - | 1.4T | 50.51 (51.60) | 55.73 (55.30) | 47.20 | 51.41 | 53.60 |
| Baichuan2-7B-Base | - | 2.6T | 46.97 (54.16) | 57.67 (57.07) | 45.76 | 52.60 | 54.00 |
| Baichuan2-13B-Base | - | 2.6T | 54.84 (59.17) | 62.62 (61.97) | 52.08 | 58.25 | 58.10 |
| ChatGLM-6B | - | 1.0T | 39.67 (40.63) | 41.17 (-) | 40.10 | 36.53 | 38.90 |
| ChatGLM2-6B | - | 1.4T | 44.74 (45.46) | 49.40 (-) | 46.36 | 45.49 | 51.70 |
| InternLM-7B | - | 1.6T | 46.70 (51.00) | 52.00 (-) | 44.77 | 61.64 | 52.80 |
| Qwen-7B | - | 2.2T | 54.29 (56.70) | 56.03 (58.80) | 52.47 | 56.42 | 59.60 |
| Llama-2-7B | - | 2.0T | 44.47 (45.30) | 32.97 (-) | 32.60 | 25.46 | - |
| Linly-AI/Chinese-LLaMA-2-7B-hf | Llama-2-7B | 1.0T | 37.43 | 29.92 | 32.00 | 27.57 | - |
| wenge-research/yayi-7b-llama2 | Llama-2-7B | - | 38.56 | 31.52 | 30.99 | 25.95 | - |
| ziqingyang/chinese-llama-2-7b | Llama-2-7B | - | 33.86 | 34.69 | 34.52 | 25.18 | 34.2 |
| TigerResearch/tigerbot-7b-base | Llama-2-7B | 0.3T | 43.73 | 42.04 | 37.64 | 30.61 | - |
| LinkSoul/Chinese-Llama-2-7b | Llama-2-7B | - | 48.41 | 38.31 | 38.45 | 27.72 | - |
| FlagAlpha/Atom-7B | Llama-2-7B | 0.1T | 49.96 | 41.10 | 39.83 | 33.00 | - |
| IDEA-CCNL/Ziya-LLaMA-13B-v1.1 | Llama-13B | 0.11T | 50.25 | 40.99 | 40.04 | 30.54 | - |
| Colossal-LLaMA-2-7b-base | Llama-2-7B | 0.0085T | 53.06 | 49.89 | 51.48 | 58.82 | 50.2 |
| Colossal-LLaMA-2-13b-base | Llama-2-13B | 0.025T | 56.42 | 61.80 | 54.69 | 69.53 | 60.3 |

ColossalChat: ChatGPT をクローンするための完全な RLHF パイプラインを備えたオープンソースソリューション。 [code] [blog] [デモ] [チュートリアル]
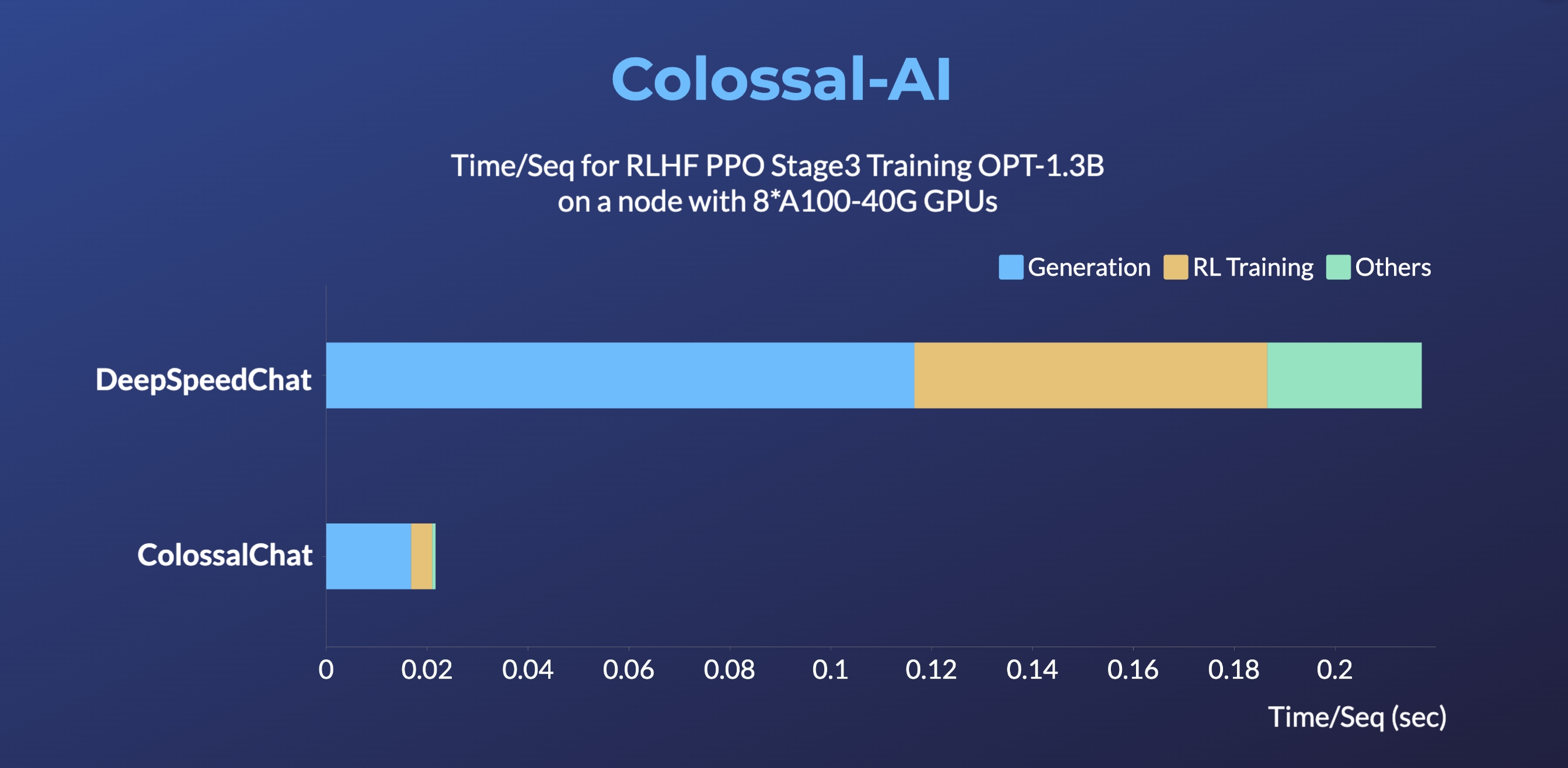
- RLHF PPO Stage3 トレーニングで最大 10 倍高速化

- シングルサーバートレーニングで最大 7.73 倍高速化、シングル GPU 推論で 1.42 倍高速化
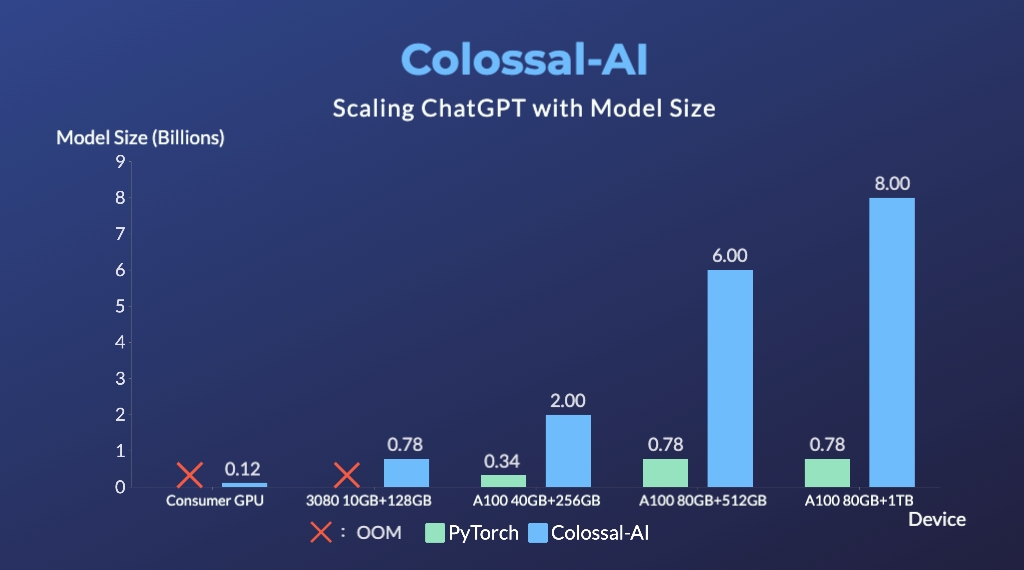
- 1 つの GPU で最大 10.3 倍のモデル容量の成長
- ミニデモのトレーニングプロセスは 1.62GB の GPU メモリのみが必要です(任意のコンシューマーグレード GPU)
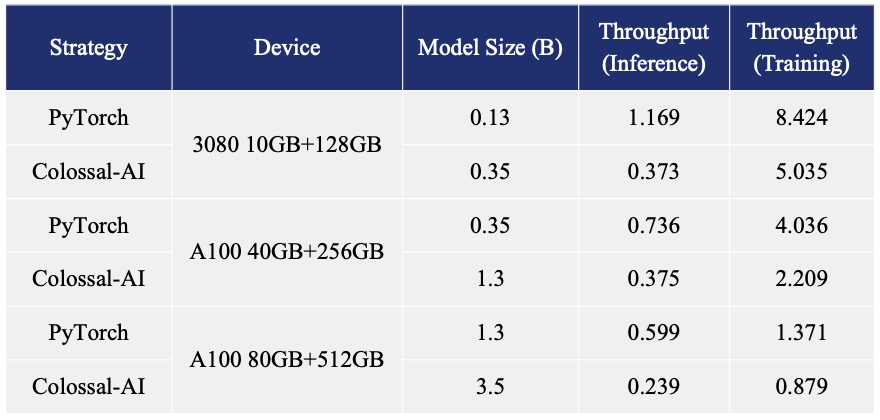
- シングル GPU で微調整モデルの容量を最大 3.7 倍増加できます
- 十分に高い実行速度を維持できます
(トップに戻る)