
![]()
オールインワン AI フレームワーク



![]()

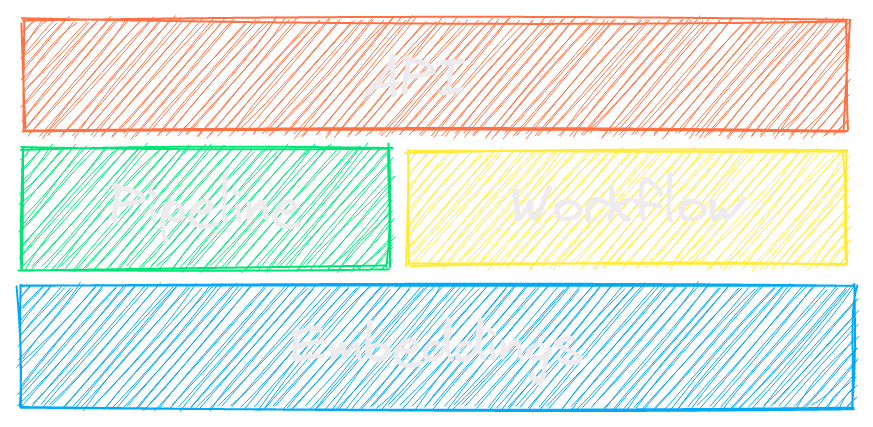
txtai は、セマンティック検索、LLM オーケストレーション、言語モデルワークフロー向けのオールインワン AI フレームワークです。


txtai の主要なコンポーネントは埋め込みデータベースであり、これはベクトルインデックス(スパースおよび密集)、グラフネットワーク、リレーショナルデータベースの統合です。
この基盤により、ベクトル検索が可能になり、大規模言語モデル(LLM)アプリケーション向けの強力な知識源として機能します。
自律型エージェント、検索拡張生成(RAG)プロセス、マルチモデルワークフローなどを構築できます。
txtai 機能の概要です:
- 🔎 SQL、オブジェクトストレージ、トピックモデリング、グラフ分析、マルチモーダルインデックスを使用したベクトル検索
- 📄 テキスト、ドキュメント、オーディオ、画像、ビデオの埋め込みを作成
- 💡 LLM プロンプト、質問応答、ラベリング、文字起こし、翻訳、要約などを実行する言語モデルを使用したパイプライン
- ↪️️ パイプラインを結合してビジネスロジックを集約するワークフロー。txtai プロセスは、シンプルなマイクロサービスからマルチモデルワークフローまで対応できます。
- 🤖 埋め込み、パイプライン、ワークフロー、および他のエージェントをインテリジェントに接続して、複雑な問題を自律的に解決するエージェント
- ⚙️ Web および Model Context Protocol(MCP)API。JavaScript、Java、Rust、Go 向けのバインディングが利用可能です。
- 🔋 すぐに始められるデフォルト設定を備えた充実した機能
- ☁️ ローカルで実行するか、コンテナオーケストレーションでスケールアウト可能
txtai は Python 3.10+、Hugging Face Transformers、Sentence Transformers、FastAPI で構築されており、Apache 2.0 ライセンスの下でオープンソース化されています。
注記
NeuML は txtai を支えている企業であり、当社のスタックを中心に AI コンサルティングサービスを提供しています。ミーティングをスケジュールするか、メッセージを送信して詳細をご確認ください。
また、txtai.cloud でホストされた txtai アプリケーションを実行する簡単で安全な方法を構築しています。

新しいベクトルデータベース、LLM フレームワーク、その他あらゆるものが毎日生まれています。なぜ txtai で構築するのでしょうか?
- pip または Docker で数分以内に起動・実行可能です
# Get started in a couple lines
import txtai
embeddings = txtai.Embeddings()
embeddings.index(["Correct", "Not what we hoped"])
embeddings.search("positive", 1)
#[(0, 0.29862046241760254)]- 組み込み API により、選択したプログラミング言語を使用してアプリケーションを簡単に開発できます
# app.yml
embeddings:
path: sentence-transformers/all-MiniLM-L6-v2CONFIG=app.yml uvicorn "txtai.api:app"
curl -X GET "http://localhost:8000/search?query=positive"- ローカルで実行 - データを異なるリモートサービスに送信する必要がありません
- マイクロモデルから大規模言語モデル(LLM)まで対応可能
- 低フットプリント - 必要に応じて追加の依存関係をインストールしてスケールアップ可能
- 例から学ぶ - ノートブックで利用可能なすべての機能をカバー
以下のセクションでは、txtai の一般的なユースケースを紹介します。70 個以上のサンプルノートブックとアプリケーションの包括的なセットも入手できます。
セマンティック検索・類似度検索・ベクトル検索・ニューラル検索アプリケーションを構築します。

従来の検索システムはキーワードを使ってデータを検索します。セマンティック検索は自然言語を理解し、同じキーワードを持つのではなく、同じ意味を持つ結果を識別します。

以下の例で始めましょう。
| ノートブック | 説明 | |
|---|---|---|
| txtai の紹介 |
txtai が提供する機能の概要 | |
| 画像を使用した類似度検索 | 画像とテキストを同じ空間に埋め込んで検索します | |
| QA データベースの構築 | セマンティック検索を使用した質問マッチング | |
| セマンティックグラフ | トピック、データ接続性を探索し、ネットワーク分析を実行します |
自律エージェント、検索拡張生成(RAG)、データとの会話、大規模言語モデル(LLM)とインターフェースするパイプラインとワークフロー。
詳細を学ぶには以下をご覧ください。
| ノートブック | 説明 | |
|---|---|---|
| プロンプトテンプレートとタスクチェーン | モデルプロンプトを構築し、ワークフローでタスクを接続します | |
| LLM フレームワークを統合 | llama.cpp、LiteLLM、およびカスタム生成フレームワークを統合します | |
| LLM を使用したナレッジグラフの構築 | LLM 駆動エンティティ抽出を使用したナレッジグラフを構築します | |
| txtai で星を解析 | 既知の星、惑星、銀河の天文学的ナレッジグラフを探索します |
エージェントは、埋め込み、パイプライン、ワークフロー、および他のエージェントを接続して、複雑な問題を自律的に解決します。
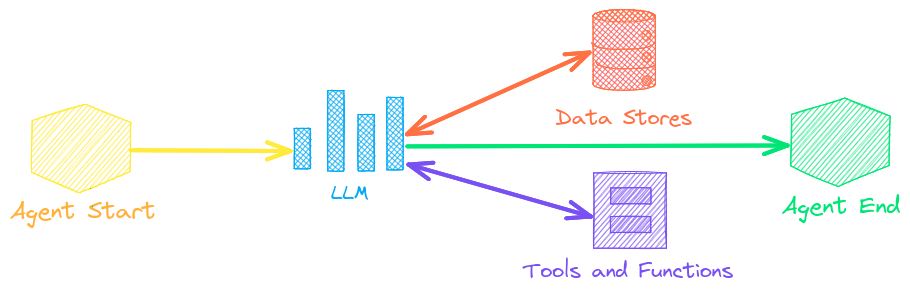
txtai エージェントは smolagents フレームワークの上に構築されています。これは txtai がサポートするすべての LLM(Hugging Face、llama.cpp、OpenAI / Claude / AWS Bedrock(LiteLLM 経由))をサポートしています。agents.md および skill.md によるエージェント プロンプティングもサポートされています。
こちらの Agent Quickstart Example をご覧ください。追加の例は以下に記載されています。
| ノートブック | 説明 | |
|---|---|---|
| エージェントに自律性を付与する | エージェントが必要に応じて反復的に問題を解決します | |
| TxtAI got skills | skill.md ファイルをエージェントと統合する | |
| Agent Tools |
txtai エージェント ツールキットについて学ぶ | |
| Analyzing LinkedIn Company Posts with Graphs and Agents | AI で社会媒体エンゲージメントを改善する方法を探索する |
検索拡張生成(RAG)は、知識ベースを文脈として出力を制限することで、LLM 幻覚のリスクを軽減します。RAG は一般的に「データとチャットする」ために使用されます。


こちらの RAG Quickstart Example をご覧ください。追加の例は以下に記載されています。
| ノートブック | 説明 | |
|---|---|---|
| Build RAG pipelines with txtai |
引用文献の作成方法を含む検索拡張生成のガイド | |
| RAG is more than Vector Search | Web、SQL、および他のソースからの文脈検索 | |
| GraphRAG with Wikipedia and GPT OSS | 深いグラフ検索を搭載した RAG | |
| Speech to Speech RAG |
RAG を使用した完全なサイクル音声から音声へのワークフロー |
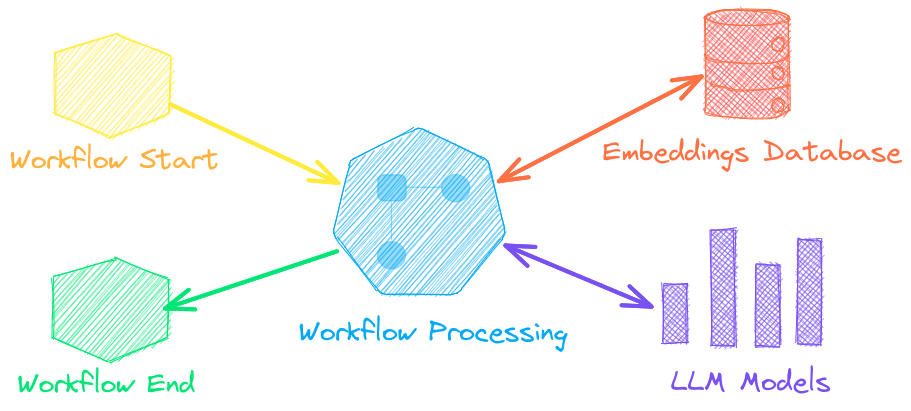
言語モデルワークフロー(セマンティックワークフローとしても知られています)は、言語モデルを接続してインテリジェント アプリケーションを構築します。


LLM は強力ですが、特定のタスク向けでより高速に動作する、より小規模で特化したモデルが多くあります。これには、抽出質問応答、自動要約、テキスト音声変換、音声文字変換、翻訳用のモデルが含まれます。
こちらの Workflow Quickstart Example をご確認ください。その他の例を以下にリストアップしています。
| ノートブック | 説明 | |
|---|---|---|
| パイプラインワークフローを実行 |
データを効率的に処理するためのシンプルだが強力な構成体 | |
| 抽象的なテキスト要約の構築 | 抽象的なテキスト要約を実行 | |
| 音声をテキストに変換 | オーディオファイルをテキストに変換 | |
| 言語間でテキストを翻訳 | 機械翻訳と言語検出を合理化 |






